|
人工智能(AI)是当今科技领域的热门话题,它正在改变着我们的生活、工作和娱乐方式。而在人工智能的发展过程中,有一种技术尤为引人注目,那就是大语言模型(Large Language Model,LLM)。大语言模型其实很早就开始研究,随着ChatGPT的出圈进入公众视野。 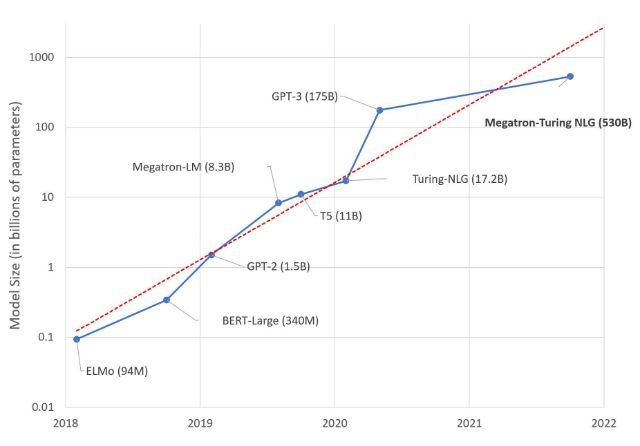 大语言模型发展历史[1],1亿参数认为是大语言模型的分界点 大语言模型是机器深度学习的一种算法,可以通过大规模数据集训练来学习识别、总结、翻译、预测和生成文本及其他内容。研究人员估计,人脑平均包含860 亿个神经元和 100 万亿个突触。为了更好的模拟人类大脑,大语言模型通过增加模型参数(例如GPT-3的参数1750亿(175B)),来模拟人脑。那么有个引发的问题,人脑有100 万亿个突触,如果模型能到100万亿参数是不是就接近真实人脑了?现在大模型方向就是走的这条路,以现在计算机的发展速度,实现起来也不是不可能。网上传说的GPT-4有100万亿参数的谣言也就是这么出来的,正好对应100万亿人脑突触。 我们的大脑是一个了不起的器官,它经过数百万年的进化而产生,而深度学习模型仅有几十年的历史,通过简单的堆参数的方式能否真正找到通向真理的道路?量变真的能够引起质变?答案只有交给未来去回答。 大语言模型的优点不再论述,这里只讲一些弊端。 1. 计算成本高。大语言模型需要消耗大量的计算资源和能源来进行训练和部署,这不仅增加了经济成本,也对环境造成了一定的影响。  训练大语言模型的耗电量和碳排放 例如GPT-3训练一次需要耗电1287MWh即128.7万度电(美国电价0.15美分/度),大概训练一次的电费成本约20万美元,即约120万人民币(很多媒体错误引用为120万美元)。ChatGPT训练了10轮,仅电费成本就需要花费1200万人民币。 2. 泛化能力差。大语言模型虽然可以在多个任务上表现出色,但是它们也容易受到输入的影响而输出不合理或者错误的内容。例如,如果给 ChatGPT 输入一个不恰当或者误导性的提示(Prompt),它可能会产生错误答案,而不是事实结果,你很轻松就能改变它的观点。 3.可解释性低。大语言模型由于参数众多,内部机制复杂,很难理解它们是如何工作的,以及它们是基于什么样的逻辑和知识来生成内容的。例如对于AI生成的内容,我们无法知道它是否正确,需要自己重新判断。用过ChatGPT的人就会知道,对于一些常识问题一本正经的胡说八道,你指出来他会说:非常抱歉,谢谢你的指出,然后修改正确的回答。 在 AI 技术圈,关于 LLM 和小模型的讨论在此之前已经持续了不短的时间,处于不同生态位置和产业环节的人都有表达自己的观点。社区和中小公司主要是小模型深度学习,并根据结果尝试反馈优化,因为承担不起训练费用和GPU租赁费。而对于大型公司,多是处于商业利益上的考量,大语言模型下,10000块A100-80G被认为是算力的入门门槛。按照一块A100卡1万美元计算,部署算力平台的成本为1亿美元,只有少数公司能够承担,这就是大公司技术的护城河。所以目前国外大模型基本是谷歌,微软,Meta(Facebook)三家。 显卡生产企业英伟达生产A100/H100,当然站在支持的这方,今年3月即将举行的GTC大会请了阿尔法go的创始人和OpenAI的创始人助阵,畅聊大语言模型,深度学习,A100/H100势必也有好的销量。 量变能否引起质变,更多的参数更大的神经网络是否会越来越像人类大脑,谁也不知道,这是一条谁也没走过的道路,现在迈出了第一步,是正确的道路还是死胡同,只有让未来回答。 正如当有记者问道:“GPT-4 是否会有类似人类推理或常识?” OpenAI创始人Sam Altman表示他们也不确定,但仍然保持“乐观”心态。 注:文章及图片转载自网络,如有侵权请联系删除 |

